Overview
This project explores the challenges of teaching Large Language Models to generate higher-order code rather than simple first-order instructions. Developed as part of a university module at Universität Potsdam, the work investigates common LLM code generation issues through the lens of the COCOBOTS domain. A code generation task where models must instruct bots to place objects on game boards.
Motivation
Current LLMs face significant limitations when generating functions in the COCOBOTS domain. The need for accurate function generation is critical as it directly impacts developer productivity and code quality. Improved accuracy in function generation can:
- Aid developers by automating repetitive coding tasks
- Reduce errors through consistent pattern recognition and abstraction
- Enhance overall productivity by generating maintainable, reusable code
The Problem: First-Order vs. Higher-Order Code
Many LLMs struggle with abstract code generation. When given instructions like "Stack a nut and washer in the 5th row and 3rd column using red for the nut and yellow for the washer," models often generate verbose, repetitive first-order code:
First-Order Code:
put(board, "nut", "red", 4, 3) put(board, "washer", "yellow", 4, 3)
While functional, this approach doesn't demonstrate true code abstraction. The ideal solution should use higher-order functions that encapsulate the logic and make the code more maintainable and reusable:
Higher-Order Code:
def m5(board, colors, x, y):
shapes = ["nut", "washer"]
for shape, color in zip(shapes, colors):
put(board, shape, color, x, y)
m5(board, ["red", "yellow"], 4, 2)
Evaluation Overview
To assess the effectiveness of fine-tuning for higher-order code generation, we conducted comprehensive evaluations across multiple models, datasets, and metrics:
Dataset
Train (4144)
Validation (500)
Test (500)
Train (1072)
Validation (130)
Test (130)
Metrics
- Exact Match (EM)
- CodeBLEU
- Execution Success (ES)
Technology Stack
Fine-Tuning Approach
Using LoRA (Low-Rank Adaptation) with Unsloth, we efficiently fine-tuned language models on curated COCOBOTS code examples. This approach significantly reduces computational costs while teaching models to recognize patterns and generate reusable function definitions.
Results - First-Order Training, Inference on Both
| Models | Exact Match | CodeBLEU | Execution Success | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | |||||||
| First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | |
| CodeLlama-7b-Instruct | 0.00% | 0.00% | 47.20% | 0.00% | 29.04% | 12.77% | 78.96% | 16.44% | 0.00% | 0.00% | 91.40% | 14.60% |
| CodeLlama-13b-Instruct | 0.00% | 0.00% | 9.80% | 0.00% | 27.08% | 13.54% | 69.81% | 16.22% | 0.00% | 0.00% | 84.80% | 11.50% |
| Llama-3.1-8B | 0.00% | 0.00% | 54.00% | 0.00% | 25.10% | 12.59% | 80.89% | 13.42% | 0.00% | 0.00% | 100% | 76.92% |
| Llama-3.2-3B | 0.00% | 0.00% | 44.40% | 0.00% | 25.48% | 12.81% | 76.97% | 29.08% | 0.00% | 0.00% | 81% | 4.60% |
| Mistral-7B-v0.1 | 0.00% | 0.00% | 100.00% | 0.00% | 25.44% | 12.86% | 100.00% | 10.68% | 0.00% | 0.00% | 100% | 65.38% |
Key Findings
- Mistral-7B achieved perfect 100% scores across all first-order metrics after fine-tuning
- All models showed 0% Exact Match on higher-order tasks, indicating no cross-order generalization
- Execution Success rates (81-100%) were significantly higher than Exact Match scores, suggesting functionally correct but syntactically different outputs
Results - Higher-Order Training, Inference on Both
| Models | Exact Match | CodeBLEU | Execution Success | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | |||||||
| First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | |
| CodeLlama-7b-Instruct | 0.00% | 0.00% | 2.60% | 7.69% | 29.04% | 12.77% | 47.27% | 72.76% | 0.00% | 0.00% | 14.60% | 41.50% |
| CodeLlama-13b-Instruct | 0.00% | 0.00% | 0.00% | 0.00% | 27.08% | 13.54% | 67.25% | 23.09% | 0.00% | 0.00% | 89.20% | 11.50% |
| Llama-3.1-8B | 0.00% | 0.00% | 0.00% | 26.15% | 25.10% | 12.59% | 52.76% | 81.66% | 0.00% | 0.00% | 14.80% | 83.80% |
| Llama-3.2-3B | 0.00% | 0.00% | 13.00% | 11.54% | 25.48% | 12.81% | 57.83% | 60.93% | 0.00% | 0.00% | 24% | 23.80% |
| Mistral-7B-v0.1 | 0.00% | 0.00% | 0.00% | 0.00% | 25.44% | 12.86% | 36.90% | 58.33% | 0.00% | 0.00% | 0% | 65.38% |
Key Findings
- Llama-3.1-8B achieved 26.15% Exact Match and 83.80% Execution Success on higher-order tasks, the best higher-order performance
- CodeBLEU scores for higher-order tasks reached 72.76-81.66%, indicating good structural similarity despite lower exact matches
- Most models struggled with first-order Exact Match (0-13%), but maintained reasonable Execution Success, showing bidirectional capability
Results - Both Training, Inference on Both
| Models | Exact Match | CodeBLEU | Exec Success | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | Pretrained | Fine-Tuned | |||||||
| First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | First-Order | Higher-Order | |
| CodeLlama-7b-Instruct | 0.00% | 0.00% | 95.40% | 44.62% | 29.04% | 12.77% | 98.36% | 90.57% | 0.00% | 0.00% | 95.40% | 54.60% |
| CodeLlama-13b-Instruct | 0.00% | 0.00% | 92.40% | 6.92% | 27.08% | 13.54% | 98.74% | 34.41% | 0.00% | 0.00% | 92.40% | 69.20% |
| Llama-3.1-8B | 0.00% | 0.00% | 54.00% | 3.08% | 25.10% | 12.59% | 80.89% | 36.52% | 0.00% | 0.00% | 100% | 22.30% |
| Llama-3.2-3B | 0.00% | 0.00% | 54.00% | 19.23% | 25.48% | 12.81% | 80.89% | 81.68% | 0.00% | 0.00% | 100% | 53% |
| Mistral-7B-v0.1 | 0.00% | 0.00% | 100.00% | 4.62% | 25.44% | 12.86% | 100.00% | 74.25% | 0.00% | 0.00% | 100% | 27.69% |
Key Findings
- Combined training achieved the best balance: 92-100% first-order Exact Match and up to 44.62% higher-order Exact Match
- CodeLlama-7b showed exceptional CodeBLEU scores (98.36% first-order, 90.57% higher-order), indicating superior code structure quality
- Three models reached 100% Execution Success on first-order tasks, demonstrating highly reliable code generation
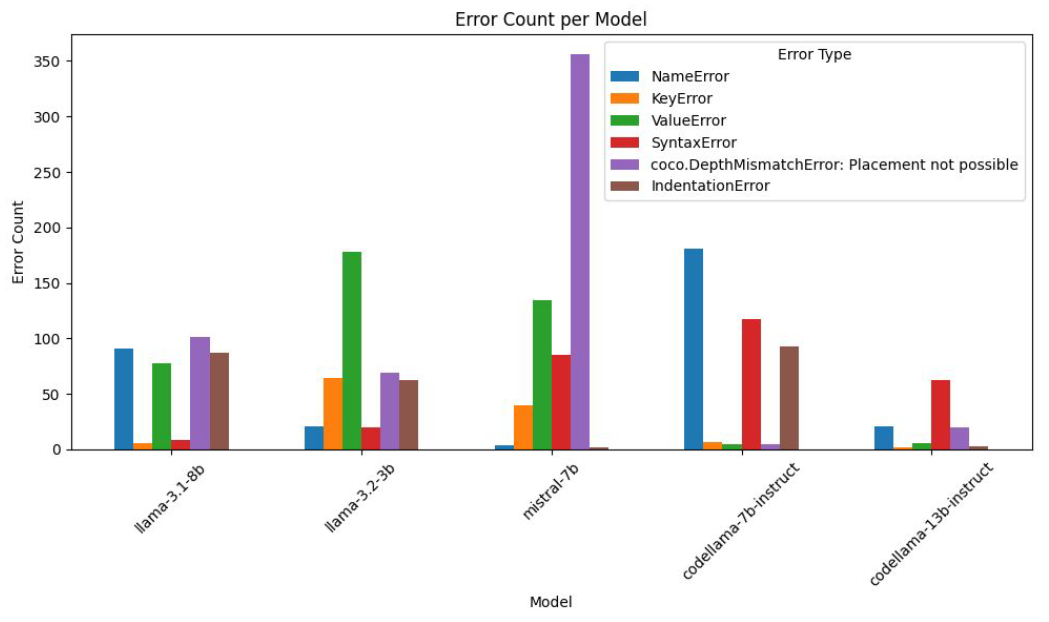
Error Analysis
Beyond overall performance metrics, we analyzed the types of errors generated by the models to understand their failure modes and identify areas for improvement:
Conclusion
The comprehensive evaluation across different training strategies revealed several key insights:
- First-Order Code Inference: Models achieved high execution success rates (~80-100%) for first-order code generation, irrespective of the training data used. This demonstrates that all training approaches effectively teach models to generate functional first-order code
- Higher-Order Code Inference: Performance varied significantly based on training strategy. Models trained only on higher-order data achieved the highest higher-order execution success (83%), while performance decreased with first-order-only training (76%) and combined data training (69%). This suggests a trade-off between specialization and versatility
- Common Error Patterns: Syntax Errors (particularly unclosed parentheses) and Placement Errors emerged as the most frequent error types across all models. The Mistral-7B model exhibited notably high placement errors, while CodeLlama models showed more balanced error distributions